Contact Advanced Research Computing
Quick Links
- Monsoon Documentation
- Submitting your first job
- Request storage
- Using the cluster: introduction
- Using the cluster: advanced
FAQs
Why is my job pending? Accordion Closed
Most of the time, questions that we get about the cluster related to why jobs are not starting(in the pending or “PD” state). There are often many different contributing factors to this.
When jobs remain pending for long periods of time, you can see why by running the “squeue” command. The reason slurm has declared your job to be “pending” will be listed in parentheses under the (REASON) column. For example, if user abc123 wanting to see all jobs that were pending, he would enter
squeue -u abc123 -s PD
The following questions on this page explain what these different reasons are and how you can avoid them in the future.
Dependency Accordion Closed
This occurs when a job “depends on” another being completed before it is allowed to start. This will only happen if a dependency is specified inside the job script using the –– dependency option.
DependencyNeverSatisfied Accordion Closed
This occurs when a job that must run first in a dependency fails. This usually means that there was an error of some kind that caused SLURM to cancel the job. When this happens, any jobs that depend on the failed job will never be allowed to run.
ReqNodeNotAvail Accordion Closed
This occurs when a requested node is either down, or there is currently a reservation in place for it. If you have requested a specific node in your job script using the “––nodelist” command, try removing this option in order to speed your job along. Slurm is very good at allocating resources, so it is often best to let it decide which nodes and processors to use in order to run your job.
To see if the node you requested is down, run
sinfo -N -l
AssocGrpCPURunMinsLimit/AssocGrpMemRunMinsLimit Accordion Closed
This occurs when either the associated account or QOS that you belong to is currently using all available CPU minutes or MEM minutes it has been allotted. Read more about Monsoon’s GrpCPURunMinsLimit.
Resources Accordion Closed
This occurs when any resources that you have requested are not currently available. This could refer to memory, processors, gpus, or nodes. For example, if you have requested the use of 20 processors and 10 nodes, and there is currently a high volume of jobs being run, it is likely that your job will remain in the pending state due to “Resources” for a long time.
Priority Accordion Closed
This occurs when there are jobs ahead of yours that have a higher priority. Not to worry, you can help alleviate this issue by updating your job time limit to a lower estimate (See the man page for the “scontrol” command). For example, if you have put “––time=1-00:00:00” in your script, Slurm will set your time limit to one day. If you know your job will not take longer than four hours, you can set this number accordingly and Slurm will give you a higher priority due to the lower time limit. This is because we have the backfill option turned on in Slurm which will enable small jobs (lower time limit) to fill the unused small time windows.
JobHeld/admin Accordion Closed
This occurs when your job is being held by the administrator for some reason. Email hpcsupport@nau.edu to find out why.
Expedite your job’s start time Accordion Closed
Sometimes jobs will remain in the pending state indefinitely due to certain settings in the job script. Here is a list of things you can do to ensure that your job gets going:
- Give your script a lower time limit (if at all possible).
- If you know the job will take a long time, try breaking it up into several different scripts that can be run separately and with shorter time limits. Consider job arrays for this. Also, the dependency option allows you to be sure that one job runs before another.
- Don’t request specific nodes.
- Don’t request more memory than you need.
- Don’t request more cpus than you are launching tasks, or threads for.
- Avoid using the “––contiguous” or “––exclusive” options, as these will limit which nodes your job can run on.
Requesting more memory Accordion Closed
Requesting a specific amount of memory in your script can be done using the “––mem” option. This amount is in megabytes (1000 MB is 1 GB). If you wanted 150 GB of memory, just multiply that number by 1000 to get the amount in MB. The example below shows the line on your script that you would add if you wanted to allocate 150 gigabytes of memory:
#SBATCH ––mem=150000
Requesting more CPUs Accordion Closed
If you would like your job to use a certain number of cpus, you may request this using the “––cpus-per-task” option. For example, if you would like each task in your script (each instance of srun you have) to use 3 cpus, you would add the following line to the script:
#SBATCH ––cpus-per-task=3
Requesting the GPU Accordion Closed
Please refer to our documentation page GPUs on Monsoon to learn how to request GPUs.
GPU availability Accordion Closed
Please refer to our documentation page GPUs on Monsoon to learn how to view GPU availability.
Job resources Accordion Closed
You can determine the efficiency of your jobs with the jobstats utility. Running “jobstats” without any flags will return all your jobs of the previous 24 hours. To see older jobs, add the -S flag followed by a date in the format YYYY-MM-DD. Example: “jobstats -S 2019-01-01”.
Here is some sample output of running jobstats:


Your efficiency is calculated with a variety of factors, including the number of CPUs you use, how long your job runs, and your memory usage.
Additional options are available. Use “jobstats -h” to see all available options.
Creating and Managing an Enterprise Group Accordion Closed
ARC’s Monsoon cluster uses NAU’s “Enterprise Groups” to define what researchers may access a given project-directory in the /projcts area.
Note: Monsoon staff are unable to modify membership of anyone’s Enterprise Group.
Monsoon and Enterprise Groups
On Monsoon, Enterprise Groups govern who can access a given project.
A PI can add/remove members to/from their Enterprise Group to control who can access their project. (Monsoon staff are unable to modify membership or ownership of Enterprise Groups.)
Creating and Managing an Enterprise Group
Enterprise Groups are managed by Monsoon’s PI’s themselves through the Directory Services tab at https://my-old.nau.edu/.
To learn how to create and manage Enterprise Groups, please read the official NAU documentation on Enterprise Groups: LDAP and Enterprise Group Maintenance [KB0014689].
Note: although it is possible to add non-Monsoon users to an Enterprise Group, those users will not have access to files (anywhere) on Monsoon.
Reviewing a Project’s Membership Via Command-Line on Monsoon
Researchers with existing projects can view the name of their project’s Enterprise Group, and review its membership, like this:
$ ls -ld /projects/hpcpub
drwxrws---+ 2 abc123 ITS-HPC-staf 4096 Sep 24 11:26 /projects/hpcpub
$ getent group ITS-HPC-staff
ITS-HPC-staff:*:11055:abc123,def456,ghi789
Licensing Accordion Closed
Licenses can be requested like any other resource in your SLURM scripts using #SBATCH ––licenses:<program>:<# of licenses>. Read the documentation on licensing for more information.
Keep commands running after disconnecting SSH Accordion Closed
Monsoon users can use the ‘screen’ command to keep commands running even after closing their terminal session/SSH client, as long as they run ‘screen’ first.
- Start a command-line shell on one of Monsoon’s login nodes
- Start a ‘screen’ session by running the ‘screen‘ command
- Initiate the desired programs/processes
- Optionally close the window/exit the SSH client
(‘screen’ is also used as a safeguard against unstable network communications)
To re-connect to a closed/lost ‘screen’ session:
- Ensure you are logged in to the same system
(e.g.:wind, rain, dtn1, ondemand) - Run ‘screen -r‘
For more in-depth information on using ‘screen’, please see our Using the ‘screen’ command page.
Configuring/moving where Anaconda keeps its data Accordion Closed
By default, Anaconda (or “conda”) stores the data for all environments you create in your home directory, in ‘/home/abc123/.conda‘ which could potentially create a quota issue if a user creates large or numerous environments. If your 10G home quota does not suffice, we can discuss expanding it to 20G. Often, however, a better workaround is to simply tell Anaconda to use your /scratch area instead of your /home area.
(Note that unix/linux systems treat files/directories that start with a period as “hidden” and often require something like an extra command flag to display them. For example, ls -l ~/ will not list your ‘.conda’ directory, but ls -la ~/ will list it, and other “hidden” files.)
To begin, start by first setting up your session such that you will be able to successfully interact with and pull information from your environment
module load anaconda3
If you have a particularly complex environment put together, or otherwise wish to make sure you have a backup set up before attempting to move where data is stored, you may first execute the following commands, in which “myenv” is replaced by the name of your environment:
conda activate myenv conda env export > myenv.yml conda deactivate
Regardless of whether or not you perform this backup, if you already have established conda environments that you wish to keep, you will have to export the existing data into a text file, such that you may later copy it over to the new location in your scratch area (If you have more than one environment that you are wishing to move, export each of your environments to their own files):
conda activate myenv conda list --explicit > env-file.txt conda deactivate
Next, using the text-editor of your choice, carefully add the following lines to the top of your ‘~/.condarc‘ file, replacing abc123 with your own user ID:
envs_dirs: - /scratch/abc123/conda/envs pkgs_dirs: - /scratch/abc123/conda/pkgs
Following this, the next step will be to create the new copies of your environments using the conda toolset. If, as stated earlier, you have more than one environment, repeat this step with each of the environment text files. At this time, if you wish, you may also opt to rename your environments by changing the term after the --name flag:
conda create --name myenv --file spec-file.txt
Now, conda environments and packages will continue be accessed/stored at ‘/scratch/abc123/conda/’. From here, all that is left to do is to delete the old conda files from the location that is no longer in use:
rm -r ~/.conda
And you should now be able to fully utilize your conda environments working from the /scratch directory
Managing and utilizing Python environments on Monsoon Accordion Closed
We utilize the Anaconda Python distribution on Monsoon. If you’d like to create a Python environment in your home to install your own packages outside of what is already provided by the distribution, do the following:
- module load anaconda
- conda create -n tensorflow_env tensorflow (where tensorflow_env is your environment name, and tensorflow is the package to be installed into your new environment)
- source activate tensorflow_env
With the environment activated, you can install packages locally into this environment via conda, or pip.
Example:
_________
#!/bin/bash
#SBATCH ––job-name=pt_test
#SBATCH ––workdir=/scratch/abc123/tf_test/output
#SBATCH ––output=/scratch/abc123/tf_test/output/logs/test.log
#SBATCH ––time=20:00
module load anaconda/latest
srun .conda/envs/tensorflow_env/bin/python test_tensorflow.py
Parallelism Accordion Closed
Many programs on Monsoon are written to make use of parallelization, either in the form of threading, MPI, or both. To check what type of parallelization an application supports, you can look at the libraries it was compiled with. First, find where you app is located using the “which” command. Then run “ldd /path/to/my/app.” A list of libraries will be printed out. If you see “libpthread” or “libgomp”, then it is likely that your software is capable of multi-threading (shared memory). Please read our segment on shared-memory parallelism for more info on setting up your Slurm script.
If you see libmpi* listed, then it is likely that your software is capable of MPI (distributed memory). Please read our segment on distributed-memory parallelism for more info on setting up your Slurm job script.
Running X11 Jobs on Monsoon Accordion Closed
Some programs run on the cluster will be more convenient to run and debug with a GUI. Due to this, the Monsoon cluster supports forwarding X11 windows over your ssh session.
Running X-Forwarding
Enable X-forwarding to your local machine is fairly straightforward.
Mac/Linux
When connecting to monsoon using SSH, add the -Y flag
ssh abc123@monsoon.hpc.nau.edu -YWindows
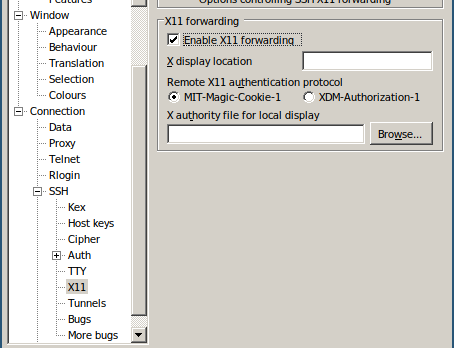
On PuTTY, in the left menu navigate to SSH->X11 and check Enable X11 forwarding
After connecting to Monsoon, running the GUI program with srun will create your window.
srun xeyesFor some programs, such as matlab, in order to ensure the window appears, add the ––pty flag to srun.
module load matlab
srun ––pty -t 5:00 ––mem=2000 matlab # Start an interactive matlab sessionRestoring Deleted Files Accordion Closed
What if I delete a file that I need?
Snapshot of all home user directories are taken twice a day. What this means is if you accidentally delete a file from your home directory that you need back, if it was created before a snapshot window, you will be able to restore that file. If you do an ls of the snapshot directory (ls /home/.snapshot), you may see something like the following:
@GMT-2019.02.09-05.00.01 @GMT-2019.02.10-18.00.01 @GMT-2019.02.12-05.00.01 latest
@GMT-2019.02.09-18.00.02 @GMT-2019.02.11-05.00.01 @GMT-2019.02.12-18.00.01
@GMT-2019.02.10-05.00.01 @GMT-2019.02.11-18.00.01 @GMT-2019.02.13-05.00.01
Each of the directories starting with @GMT are a backup. if my userid is ricky I can check my files like the following:
ls -la /home/.snapshot/@GMT-2019.02.12-18.00.01/ricky
if I know I had my file before 6pm on the 12th. I would see all of the files that I had at the time of the snapshot. If there were a file called dask_test.py that I needed to restore from that snapshot, I could type in the following:
cp /home/.snapshot/@GMT-2019.02.12-18.00.01/ricky/dask_test.py /home/ricky
Your file would then be restored.
Requesting Certain Node Generations Accordion Closed
Monsoon has four generations of nodes ordered by age (oldest first):
- Sandy Bridge Xeon, 4 socket, 8 core per socket, 2.20GHz, 384GB mem # request with #SBATCH -C sb
- Haswell Xeon, 2 socket, 12 core per socket, 2.50GHz, 128GB mem # request with #SBATCH -C hw
- Broadwell Xeon, 2 socket, 14 core per socket, 2.40GHz, 128GB mem # request with #SBATCH -C bw
- Skylake Xeon, 2 socket, 14 core per socket, 2.60GHz, 196GB mem # request with #SBATCH -C sl
To select a certain generation, just put #SBATCH -C <generation> in the job. For instance to have a job run on Broadwell nodes only:
#!/bin/bash #SBATCH ––job-name=myjob # job name #SBATCH ––output=/scratch/abc123/output.txt # job output #SBATCH ––time=6:00 #SBATCH ––workdir=/scratch/abc123 # work directory #SBATCH ––mem=1000 # 2GB of memory #SBATCH -C bw # select the Broadwell generation # load a module, for example module load python/2.7.5 # run your application, precede the application command with srun # a couple example applications ... srun date srun sleep 30 srun date
How to request specific model of GPU Accordion Closed
Please refer to our documentation page GPUs on Monsoon to learn how to request specific GPU models.
RStudio Missing Project Folder Accordion Closed
system(“ls /projects/<insert proj name>/PROJ_DETAILS”)
Support for rgdal Accordion Closed
Often researchers utilizing R, and geospatial tools will lean on a package called “rgdal”. In order to utilize rgdal on monsoon, a number of external software packages must first be made available to R both for the initial “rgdal” installation, as well as for subsequent usage.
We have prepared a full explanation of the process on our HPC forum, here: How do I install/use the ‘rgdal’ package for R on Monsoon?
Similarly, a more generalized explanation of how to use R modules with Monsoon is here: What is the preferred way to install R packages/libraries on Monsoon?
Using conda environments in the ondemand jupyter app Accordion Closed
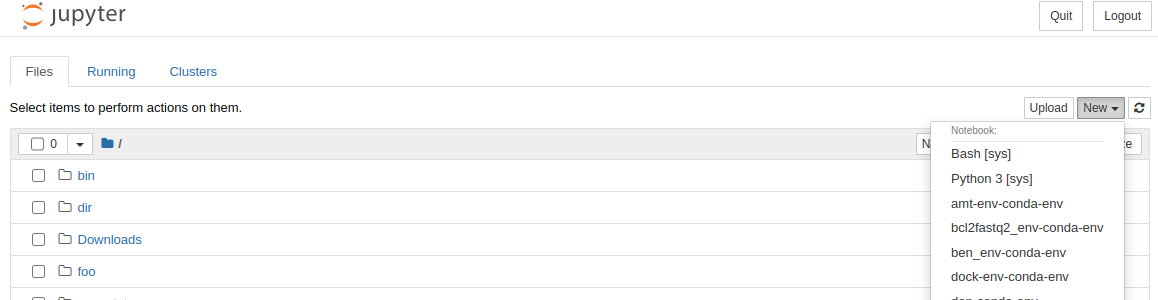
The jupyter app for ondemand (located here) automatically looks for any conda environments you may have installed on monsoon. If any of these environments has python and ipykernel, then the app loads them up and you can select them as a kernel named *-conda-env. This gives you access to specialized python modules that are not in the base environment, like BeautifulSoup for example.
Here’s how you can select a kernel on the home screen on juptyer:
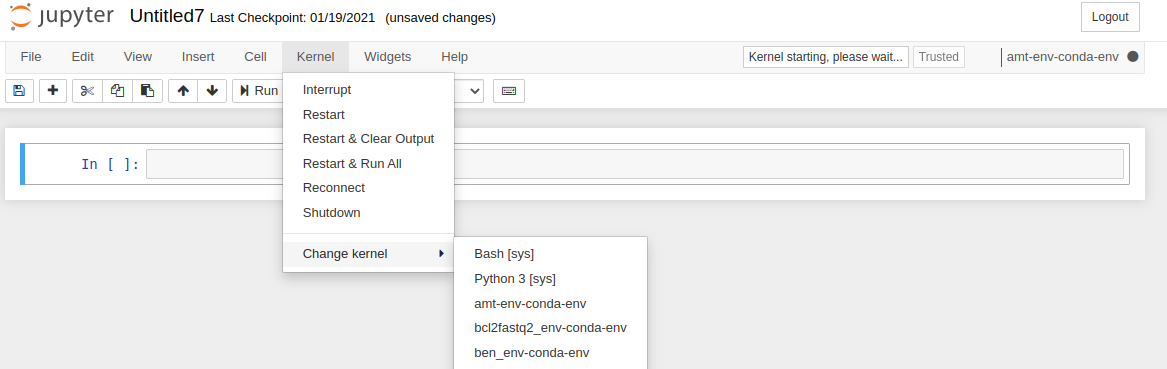
Or from within a notebook:
Here’s how you can install the ipykernel package in your conda env (replace “myenv” with your conda environment name):
module load anaconda3
conda activate myenv
conda install ipykernel
If the conda install is successful you should be able to load ipykernel without error like this:
python3 -c 'import ipykernel'
And there will be a jupyter-kernelspec executable in the environment:
# if this command prints out a path different from your environment's /bin
# then jupyter won't see it
# this would be from an error with the ipykernel install for your conda env
which jupyter-kernelspec
If you are still using python2 then you may have to install backports like this:
conda install backports.functools_lru_cache
conda stuck on solving env Accordion Closed
A common issue with conda is when a conda install command gets stuck on “Solving environment”. This means that conda is looking through the conda channels for the packages to install (conda channels are like repos, they stand for web addresses that conda’s API uses to search for packages). Each conda install is broadly a two step process: 1. solving the environment, 2. downloading prebuilt package files. There is no indication of how long the solving environment process can take, and for packages with a complex set of dependencies, it can take an excessive 10+ minutes.
$ conda install -c syanco r-amt
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Collecting package metadata (repodata.json): /
There are a few conda arguments you can set to try to improve the speed of conda. But to save time, first determine if you need to go through this process, if you want to make an exact copy of a conda env you can export it and import it instead. The export step creates a file with a list of URLs so conda doesn’t need to spend any time scanning package lists for compatible dependencies (see this official documentation page).
Helpful arguments:
- -c <channels>
- Adds a channel from which to search for the package
- By default you should have the “default” and “conda-forge” channels defined in your ~/.condarc
- You should always specify this option, can speed up conda when used with the –override-channels option
- –override-channels
- ignores any channels from your ~/.condarc, must be combined with the -c option
- –strict-channel-priority
- tells conda to not search in the next channel once a package match is found in a higher priority channel
- most impact of these options
For example, this command was able to install the r-amt package in a few minutes instead of getting indeterminably stuck.
conda install --strict-channel-priority -c syanco r-amt
The conda environment installation process is not efficient and there seems to be little interest from the maintainers in improving this since they see installation as a one-time setup step for most users.
For more information refer to the online documentation or run this command on monsoon:
conda install --help